本文来自“架构师技术联盟”,“2023新型算力中心调研报告(2023)”。
链接:https://mp.weixin.qq.com/s/_ascEAu1pdtB85ED0PC2jg
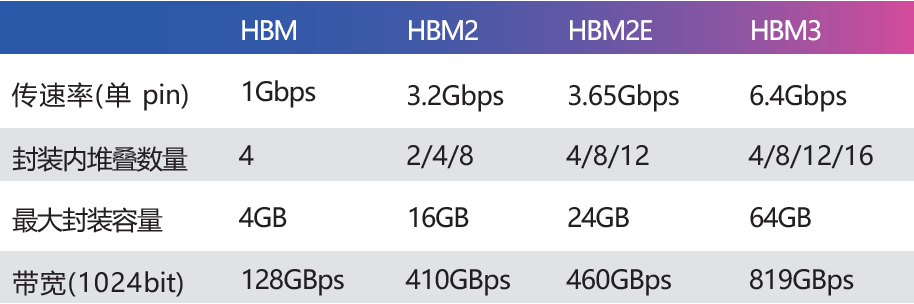
HBM(High Bandwidth Memory,高带宽内存)是 2014 年 AMD、SK海力士(SK Hynix)共同发布的,使用 TSV 技术将数个 DRAM Die(晶片)堆叠起来,大幅提高了容量和数据传输速率。
随后三星、美光、NVIDIA、Synopsys 等企业积极参与这个技术路线,标准化组织 JEDEC 也将 HBM2 列入标准(JESD235A),并陆续迭代了HBM2e(JESD235B)以及HBM3(JESD235C)。得益于堆叠封装,以及巨大的位宽(单封装 1024bit),HBM 提供了远超其他常见内存形态(DDR DRAM、LPDDR、GDDR 等)的带宽和容量。
典型的实现方式是通过 2.5D 封装将 HBM 与处理器核心连接,这在 CPU、GPU 等产品中均有应用。早期也有观点把 HBM 视作 L4 Cache,从 TB/s 级的带宽角度看,也算合理。而从容量角度,HBM 就比 SRAM 或 eDRAM 大太多了。由此,HBM 既可以胜任(一部分)的工作,也可以当做高性能内存使用。
AMD 是 HBM 的早期使用者,发展至今,AMD Instinct MI250X 计算卡在单一封装内集成了 2 颗计算核心和 8 颗 HBM2e,容量共 128GB,带宽达到 3276.8GB/s。
NVIDIA 应用 HBM 的主要是专业卡,其 2016 年的 TESLA P100 的 HBM 版搭配了 16GB HBM2,随后的 V100 搭配了 32GB HBM2。目前当红的 A100 和 H100 也都有 HBM 版,前者最大提供 80GB HBM2e、带宽约 2TB/s;后者升级到 HBM3,带宽约 3.9TB/s。
华为的昇腾 910 处理器也集成了 4 颗 HBM。对于计算卡、智能网卡(SmartNIC)、高速 FPGA 等产品,HBM 作为一种 GDDR 的替代品,应用已经非常成熟了。
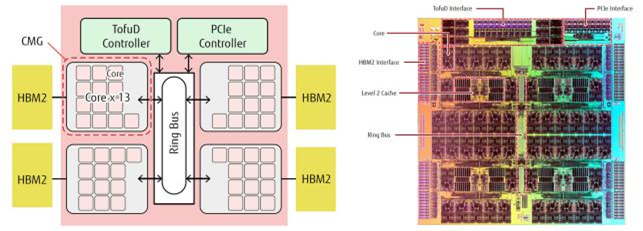
CPU 也已开始集成 HBM,其中最突出的案例是曾经问鼎超算 TOP500 的富岳(Fugaku),使用富士通研发的 A64FX 处理器。A64FX 基于 Armv8.2-A,采用 7nm 制程,每封装内集成了 4 颗 HBM2,容量 32GB,带宽 1TB/s。
英特尔在 2023 年 1 月中与第四代至强可扩展处理器一同推出的至强 Max 系列,在前者的基础上集成了 64GB 的 HBM2e。这些 HBM2e 可以作为内存独立使用(HBM Only 模式),也可以搭配 DDR5 内存共同使用(HBM Flat Mode 和 HBM Caching Mode 两种工作模式)。

值得一提的是,目前 HBM 与处理器“组装”在一起都需要借助
硅中介层。传统的 ABS 材质基板等难以胜任超高密度的触点数量和高频率。硅中介层有两种技术思路,代表是台积电的CoWoS(chip-on-wafer-on-substrate)和英特尔的EMIB(Embedded Multi-Die Interconnect Bridge)。
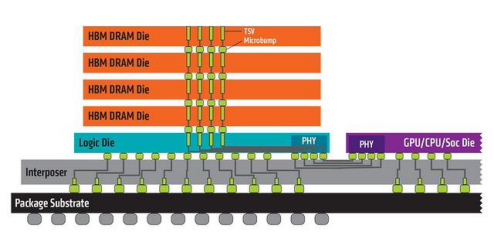
台积电 CoWoS-S 通过硅中介层承载处理器和 HBM。其硅中介层也被称为硅基础层,因为中介层会完全承载其他芯片。换句话说,处理器和若干 HBM 的投影面积决定了硅基础层的大小,而基础层的面积会限制 HBM 的使用数量(常见的就是 4 颗)。硅中介层使用 65nm 之类的成熟工艺制造,其成本并不高昂,但尺寸受限于光刻掩膜尺寸。
这就成为了早期 HBM 应用的瓶颈——需要 HBM 的往往是高性能的大芯片,而大芯片的规模本身就已经逼近了掩膜尺寸极限,给HBM留下的面积非常有限。到了 2016 年,台积电终于突破了这个限制,实现 1.5 倍于掩模尺寸的中介层,从此单芯片内部可封装 4 颗 HBM,这就是当前市场上的主流形态了。
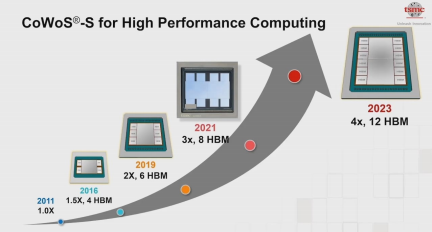
2019 年,台积电宣称实现 2 倍掩膜尺寸,可以支持 6 颗 HBM 了。很快,2020年发布的 NEC SX-Aurora TSUBASA 矢量处理器,集成6 颗共 48GB HBM2;同年的英伟达 A100 则是 6 颗共 40GB HBM2e(有一颗HBM未启用)。
至于可以封装 12 颗 HBM 的巨型芯片,预计面积将达到 3200 平方毫米(mm²)。硅中介层的面积如此发展,下一个瓶颈就是硅晶圆的切割效率了。
另一种思路是英特尔的 EMIB,使用的硅中介层要小得多。以第四代英特尔至强可扩展处理器的渲染图为例,棕色的小方块就是 EMIB 的“桥”,用以将 4 个 XCC 的 die 拼为一个整体;而在至强 Max 系列中,每个 die 还需要通过 EMIB 去连接对应的 HBM 芯片。结合 HBM 的架构示意图可以看出,英特尔认为只需要通过硅中介层连接内存和处理器的 PHY 部分,其他信号依然可以直通基板。整体而言,EMIB 充分利用了硅中介层和有机载板的技术特点和电气特性,但也存在组装成本高的缺点(需要在有机载板中镶嵌,增加了工艺复杂度,限制了载板的选择)。

当然,对于更复杂的“组装”,英特尔也有对应的方案,如代号 Ponte Vecchio 的英特尔数据中心 GPU Max 系列整合了基于 5 种制造工艺生产的 47 个小芯片,其中的基础层(Base Die)的面积为650mm²。该产品综合了 Foveros 3D封装和 EMIB 2.5D 封装的特点,纵向横向齐发展。
英特尔数据中心 Max GPU 系列引入了 Base Tile的概念,姑且称之为基础芯片。相对于中介层的概念,我们也可以把基础芯片看作是基础层。基础层表面上看与硅中介层功能类似,都是承载计算核心、高速 I/O(如 HBM),但实际上功能要多得多。硅中介层的本质是利用成熟的半导体光刻、沉积等工艺(65nm 等级),在硅上形成超高密度的电气连接。而基础层更进一步:既然都要加工多层图案,为什么不把逻辑电路之类的也做进去呢?

Intel 在 ISSCC2022 中展示了英特尔数据中心 Max GPU 的Chiplet(小芯片)架构,其中,基础芯片面积为 640mm²,采用了 Intel 7 制程——这是目前Intel用于主流处理器的先进制程。为何在“基础”芯片上就需要使用先进制程呢?因为 Intel 将高速 I/O 的 SerDes 都集成在基础芯片中了,其作用有点儿类似 AMD 的 IOD。这些高速 IO 包括 HBM PHY、Xe Link PHY、PCIe 5.0,以及,这一节的重点:Cache。这些电路都比较适合 5nm 以上的工艺制造,将它们与计算核心解耦后重新打包在一个制程之内是相当合理的选择。
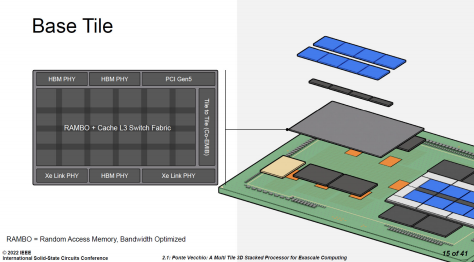
英特尔数据中心 Max GPU 系列通过 Foveros 封装技术在基础芯片上方叠加 8 颗计算芯片(Compute Tile)、4 颗 RAMBO 芯片(RAMBO Tile)。计算芯片采用台积电 N5 工艺制造,每颗芯片都自有 4MB L1 Cache。RAMBO是“Random Access Memory, Bandwidth Optimized”的缩写,即为带宽优化的随机访问存储器。独立的 RAMBO 芯片基于 Intel 7 制程,每颗有 4 个 3.75MB 的 Bank,共 15MB。每组 4 颗 RAMBO 共提供了 60MB 的 L3 Cache。此外,在基础芯片中也有 RAMBO,容量有 144MB,外加 L3 Cache 的交换网络(Switch Fabric)。
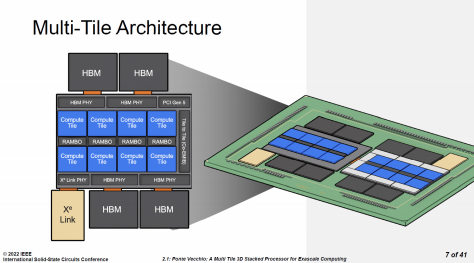
因此,在英特尔数据中心 Max GPU 中,基础芯片通过了 Cache 交换网络,将基础层内的 144MB Cache,与 8 颗计算芯片、4 颗 RAMBO 芯片的 60MB Cache 组织在一起,总共 204MB L2/L3 Cache,整个封装是两组,就是 408MB L2/L3 Cache。
英特尔数据中心 Max GPU 的每组处理单元都通过 Xe Link Tile 与另外 7 组进行连接。Xe Link 芯片采用台积电 N7 工艺制造。

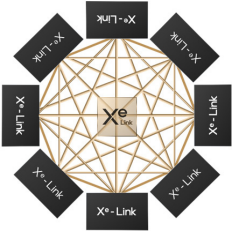
前面已经提到,I/O 芯片独立是大势所趋,共享 Cache 与 I/O 拉近也是趋势。英特尔数据中心 Max GPU 将 Cache 与各种高速 I/O 的 PHY 集成在同一芯片内,正是前述趋势的集大成者。至于 HBM、Xe Link 芯片,以及同一封装内相邻的基础芯片,则通过 EMIB(爆炸图中的橙色部分)连接在一起。

根据英特尔在 HotChips 上公布的数据,英特尔数据中心 Max GPU 的 L2 Cache 总带宽可以达到 13TB/s。考虑到封装了两组基础芯片和计算芯片,我们给带宽打个对折,基础芯片和 4 颗 RAMBO 芯片的带宽是 6.5TB/s,依旧远远超过了目前至强和 EPYC 的 L2、L3 Cache 的带宽。其实之前 AMD 已经通过了指甲盖大小的 3D V-Cache 证明了 3D 封装的性能,那就更不用说英特尔数据中心 Max GPU 的 RAMBO 及基础芯片的面积了。

回顾一下 3D V-Cache 的弱点——“散热”不良,我们还发现将 Cache 集成到基础芯片当中还有一个优点:将高功耗的计算核心安排在整个封装的上层,更有利于散热。再往远一些看,在网格化的处理器架构中,L3 Cache 并非简单的若干个块(切片),而是分成数十甚至上百单元,分别挂在网格节点上的。基础芯片在垂直方向可以完全覆盖(或容纳)处理器芯片,其中的 SRAM 可以分成等量的单元与处理器的网格节点相连。
换句话说,对于网格化的处理器,将 L3 Cache 移出到基础芯片是有合理性的。目前已经成熟的 3D 封装技术的凸点间距在 30~50 微米的量级,足够胜任每平方毫米内数百至数千个连接的需要,可以满足当前网格节点带宽的需求。更高密度的连接当然也是可行的,10 微米甚至亚微米的技术正在推进当中,但优先的场景是 HBM、3D NAND 这种高度定制化的内部堆栈的混合键合,未必适合 Chiplet 对灵活性的要求。
HBM 是 GDDR 存储器的替代品,可用于 GPU 和加速器。GDDR 存储器旨在以较窄的通道提供更高的数据速率,进而实现必要的吞吐量,而 HBM 存储器通过 8 条独立通道解决这一问题,其中每条通道都使用更宽的数据路径(每通道 128 位),并以 2Gbps 左右的较低速度运行。因此,HBM 存储器能够以更低的功耗提供高吞吐量,而规格上比 GDDR 存储器更小。HBM2 是目前该类别中最常用的标准,支持高达 2.4Gbps 的数据速率。
HBM2 DRAM 最多可叠加 8 个 DRAM 晶圆(包括一个可选的底层晶圆),可提供较小的硅片尺寸。晶圆通过 TSV 和微凸块相互连接。通常可用的密度包括每个 HBM2 封装 4 或 8GB。
除了支持更多的通道外,HBM2 还提供了一些架构更改,以提高性能并减少总线拥塞。例如,HBM2 具有“伪通道”模式,该模式将每个 128 位通道分成两个 64 位的半独立子通道。它们共享通道的行和列命令总线,却单独执行命令。增加通道数量可以通过避免限制性时序参数(例如 tFAW)以在每单位时间激活更多存储体,从而增加整体有效带宽。标准中支持的其他功能包括可选的 ECC 支持,可为每 128 位数据启用 16 个错误检测位。

